Network Participants
Traditional blockchains requiring every node to re-execute all transactions face significant drawbacks that hinder scalability, decentralization, and efficiency. This creates a problem when a blockchain wants to scale up its performance: it needs to scale up the specs for all nodes in the network. This is not wanted as fewer participants are able to join the network.
At RISE, we focus on delivering low-latency service with different types of services. We notice that each service has different assumptions on security as well as node requirements. Therefore, it is essential to enable different services to run on different types of machines. Together with different optimization strategies, nodes are aided by the sequencer when performing state updates, further lowering hardware requirements to minimums.
The following figure depicts network participants in RISE's architecture.
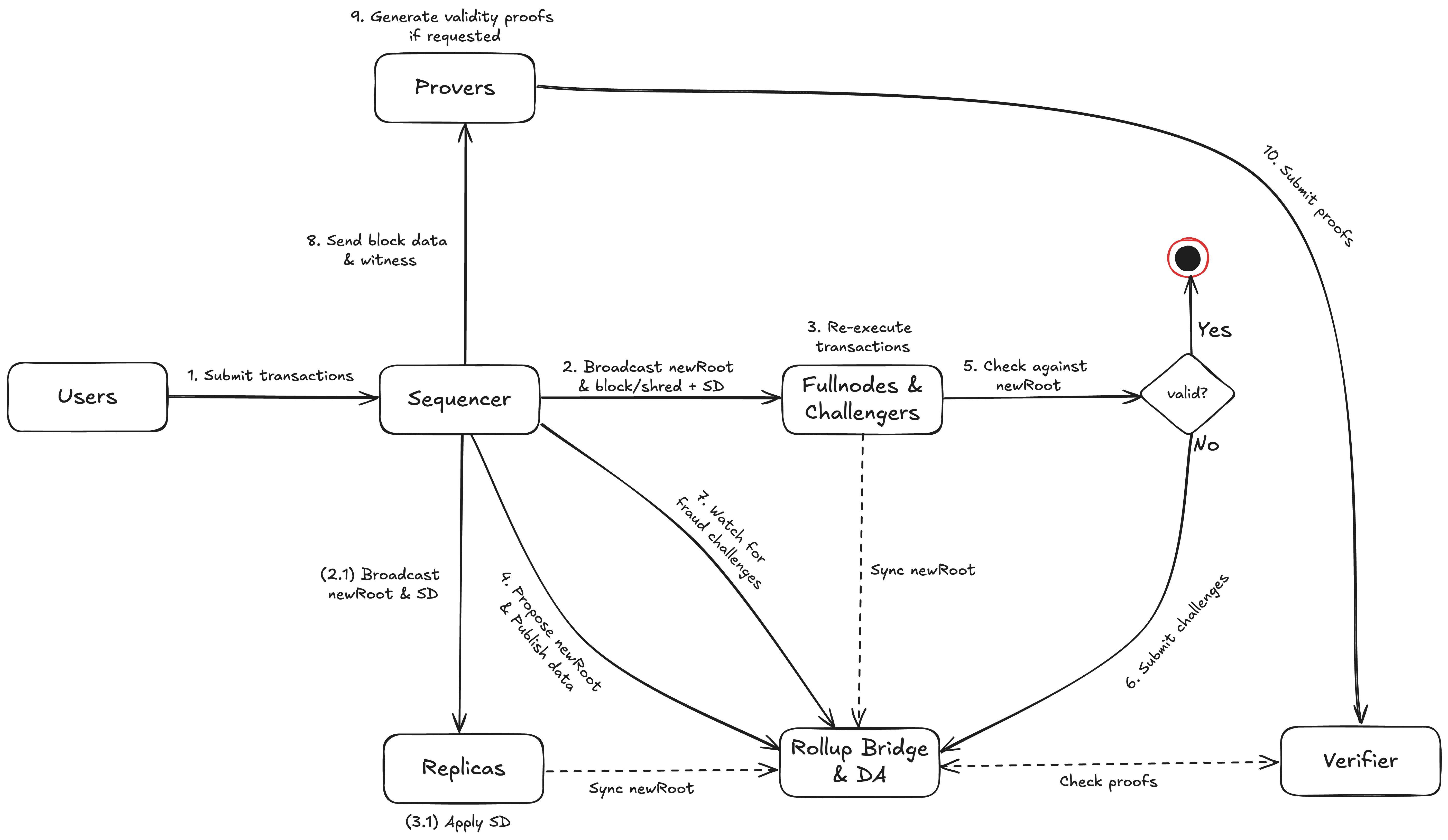
In this doc, we use Capitalized words to denote distinct types of network participants. This convention helps clearly differentiate key roles such as Sequencers, Replicas, Fullnodes, Challengers, and Provers emphasizing their specific responsibilities within the network.
Sequencer
Sitting at the heart of our architecture is the Sequencer, a highly-specialized machine responsible for ordering, processing, batching, and submitting transactions from the rollup to the L1 for final settlement. RISE's execution engine is highly optimized to allow our Sequencer to achieve massive performance without requiring enormous hardware specs.
While pevm allows transactions to be processed in parallel with ~2x speedup compared to sequential executions, our CBP starts pre-executing transactions while they are residing in the mempool, enabling execution to happen as early as possible. Then, pre-executed results are incrementally gathered in
After each
Replicas
Replicas are nodes that need to keep up with the chain's progression but do not necessarily want to re-execute transactions. Examples of such nodes include indexing services, block explorers or archival nodes. Replicas address the traditional bottlenecks of re-executing transactions by simply applying state-diffs provided by the Sequencer. This allows them to keep up with the chain's progression while running on commodity hardwares.
Regarding security, Replicas have to place some trusts on the Sequencer node, or other Fullnodes to detect Sequencer's misbehaviors. They rely on fraud proofs (governed by some fullnodes) to ensure the state diffs are indeed valid.
Fullnodes
Fullnodes re-execute transactions received from the Sequencer to ensure they are not cheated by the Sequencer. By doing this, they are able to independently verify new state updates. Applications like CEXes often maintain a Fullnode to enable faster deposits or withdrawals. They do not have to wait for the long challenge window to confirm users' transactions.
As a trade-off of security, a Fullnode must have higher hardware requirements than a Replica. However, a Fullnode maintains much lower hardware requirements than the Sequencer because when it synchronizes transactions from the Sequencer, it also receives additional metadata (e.g, transaction graphs, state-diffs, etc.), allowing it to re-execute transactions in a faster manner.
Challengers
As an L2, we also need a special party to submit challenges to the L1 when it detects a misbehavior of the Sequencer. This party is called Challenger. A Challenger must maintain a Fullnode to be able to re-execute transactions provided by the Sequencer. We only need a single honest Challenger to maintain the security of the L2 chain.
Provers
As we will evolve to a hybrid rollup, our architecture will also be incorporated with Provers who rely on specialized hardware accelerators(e.g, FPGA, GPU) to generate validity proofs when a fraud challenge is triggered.
When requested, Provers will request sufficient block data and witnesses from the Sequencer to start proof generation. After the proof are generated, Provers (or anyone else) submit the proofs to the L1 for challenge resolution. Failure in generating proofs on time will get the Sequencer slashed.
Note that Provers do not need to keep up with the chain's progression. This is because Provers only need related data for proof generation, thus they can use a much lower bandwidth or hardware requirements (not accounting for the FPGA or GPU used for proof generation). Furthermore, Provers can be only activated when a challenge is triggered (if the Sequencer behaves honestly, we will never need to use Provers), therefore, operating Provers is extremely cheap.
Hardware Specs
| Node Type | Sync Method | Security | Hardware Requirements |
|---|---|---|---|
| Sequencer | Self-execution | High | 32GB RAM |
| Lightnodes | State-diff appliance | Low, depending on fraud proofs | 8-16GB RAM |
| Fullnodes | Re-execution with aids | High, same as the Sequencer | 16-32GB RAM |
| Challengers | Same as Fullnodes | High, same as Fullnodes | 16-32GB RAM |
| Provers | Trusting the Sequencer | N/A | Depending on proving services, rarely used |
Table. Different types of nodes.