Block Production
In typical Layer 2 systems, block production follows a strictly sequential process, where only a little portion of the total blocktime is spent on actual transaction execution. This inefficiency stems from the traditional flow.
- Consensus (C). Deriving L1 transactions and new block attributes. This phases blocks all other operations.
- Execution (E). Executing derived transactions as well as L2 transaction from mempool. Execution is CPU-extensive.
- Merkleization (M). Sealing the block by computing the new commitment to the state. Merkleization is IO-intensive and increases in cost as state size grows.

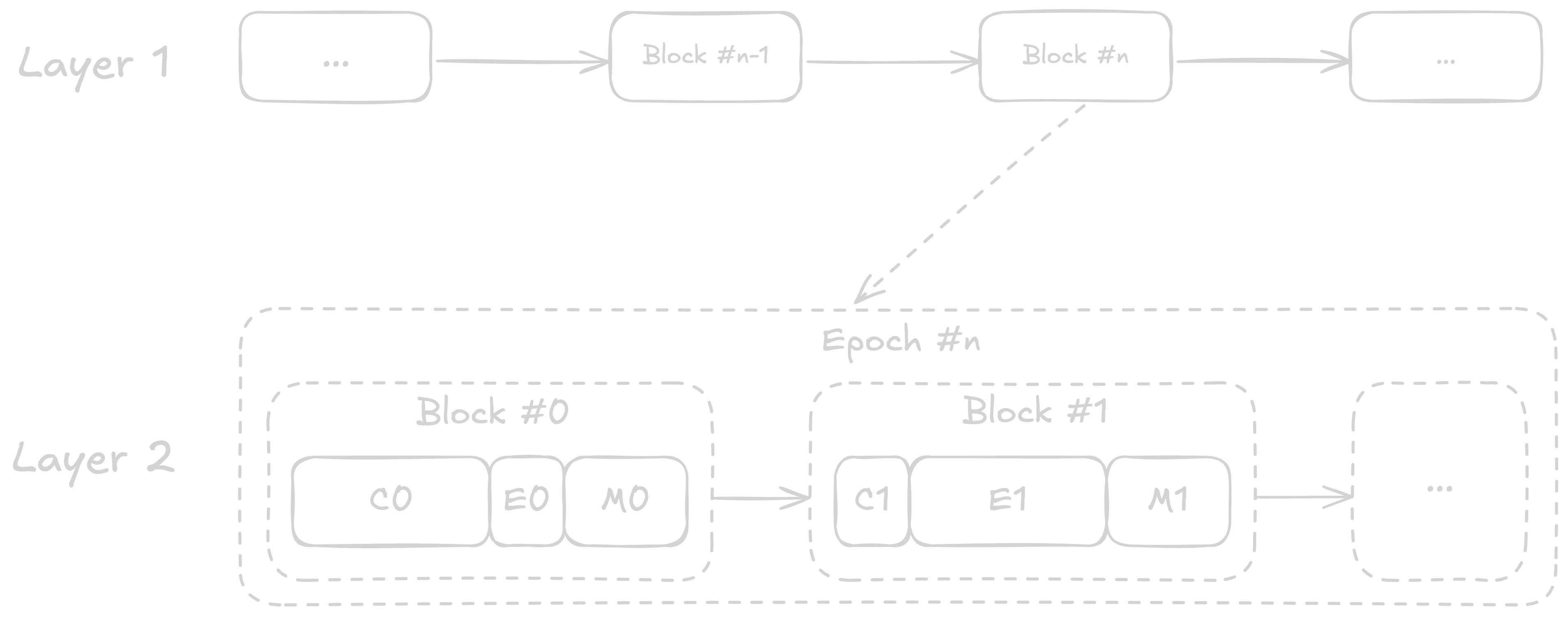 A typical block pipeline for an L2 with a one-second block time and large state. The block
A typical block pipeline for an L2 with a one-second block time and large state. The block gasLimit will be limited by how much gas can be processed in the time allocated to execution; however, in this system, execution accounts for only a minority of the block-building pipeline. The first block in an epoch has longer consensus time due to L1 and deposit derivation.
During the block-building pipeline, most of the blocktime is allocated to consensus and merkelization, leaving a tiny portion of total blocktime for execution. This insufficient use of blocktime leads to poor performances on many L2s.
Execution-Merkelization Separation
To speed-up the execution time, many Ethereum clients separate their databases for execution and merkleization. During execution, block executors use a flat database (flatDB) to read states. The flatDB provides
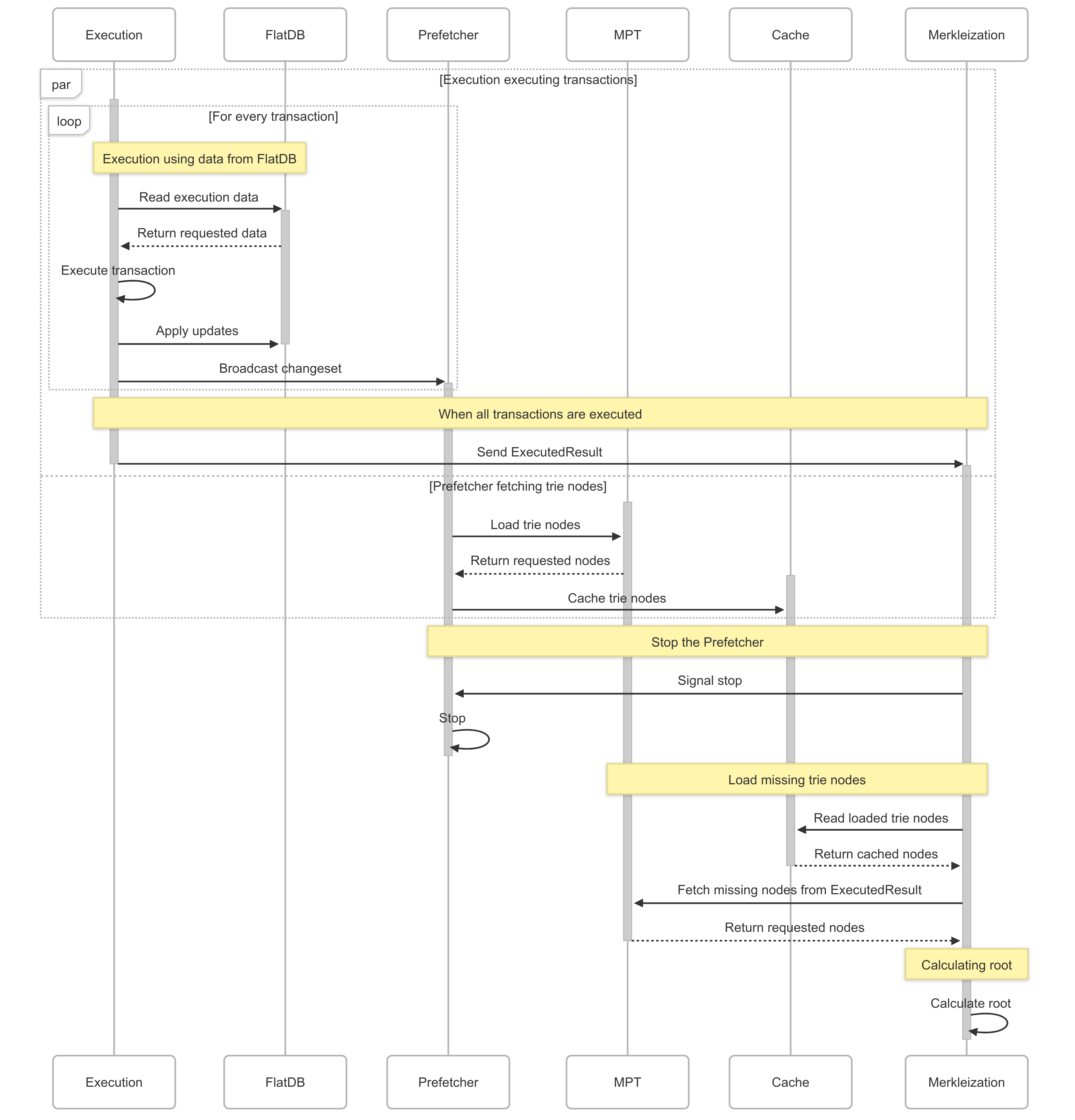
Furthermore, to make use of idle time when execution happen, a Prefetcher is implemented to prefetch trie nodes that are not present in the memory for later use in merkleization.
Continuous Block Pipeline (CBP)
Observe that because execution and merkleization can operate on different databases,
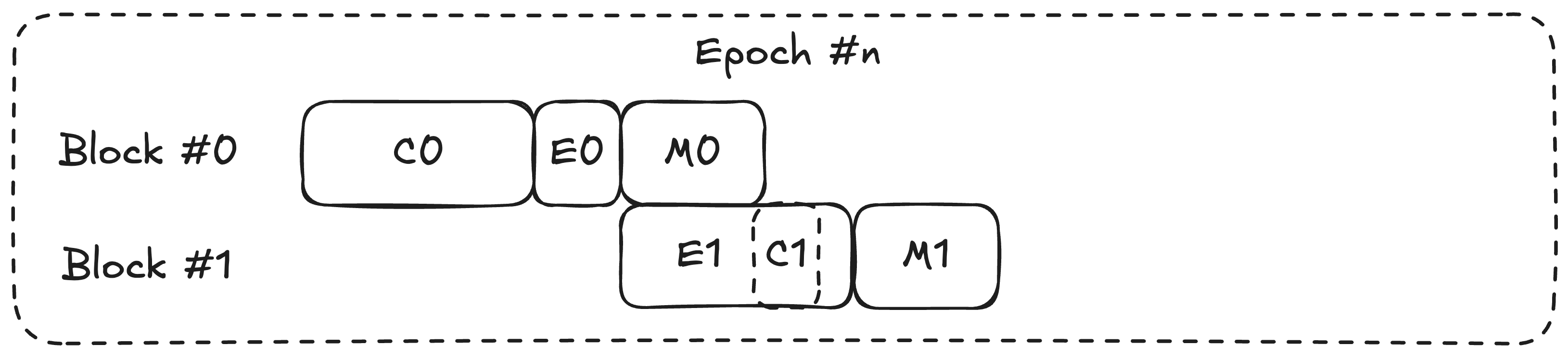
 Execution of the next block can start as soon as the execution of the previous block finishes.
Execution of the next block can start as soon as the execution of the previous block finishes.
The idea is simple, we perform execution if there are transactions residing in the mempool. To illustrate, we consider two cases.
- First L2 block in an epoch. For this block, consensus must derive new L1 block information and include L1→L2 deposited transactions. Therefore, execution of this block must be performed after consensus. This is because deposited transactions are more prioritized and might invalidate L2 transactions.
- Other blocks in an epoch. L1 information within an epoch is the same for all epoch, therefore, consensus for these block mostly depends on the previous block. Since there is no L1-derived transaction in these blocks, the execution of these block can safely start as soon as the execution of the previous block finishes.
This approach offers some benefits.
- Continuous execution of transactions. The execution thread monitors the mempool for transactions and executes them in multiple block segments, no longer waiting for consensus to request a new block.
- Higher execution throughput. Execution of the next block happens at the same with merkleization of the current block. This allows to allocate more time for execution, thus increasing the execution throughput.
- Optimized mempool processing. A new mempool structure balances latency and throughput by pre-ordering transactions to minimize shared states and maximize parallel execution.