# RiseDB (/docs/rise-evm/rise-db)
# RiseDB
## Motivation
Every transaction in a blockchain updates state: account balances change or contract updates, and historical records accumulate. Managing this state efficiently is critical to blockchain performance. However, traditional state management architectures face significant bottlenecks that limit throughput and increase latency.
The current state storage uses a two-layered architecture.
* **Merkle Patricia Trie (MPT)**. An authenticated data structure that guarantees data integrity and is typically built using a Merkle tree-like structure. It also provides a mechanism to verify the presence of specific data within the state. Nodes in the ADS are usually connected via hashes, and each node is stored in the underlying database
* **Backend database**. A component that helps persist data to disks; manages physical storage and retrieval; and handles compaction and organization of data. This backend database is often LSM-based.
This diagram illustrates the structure:
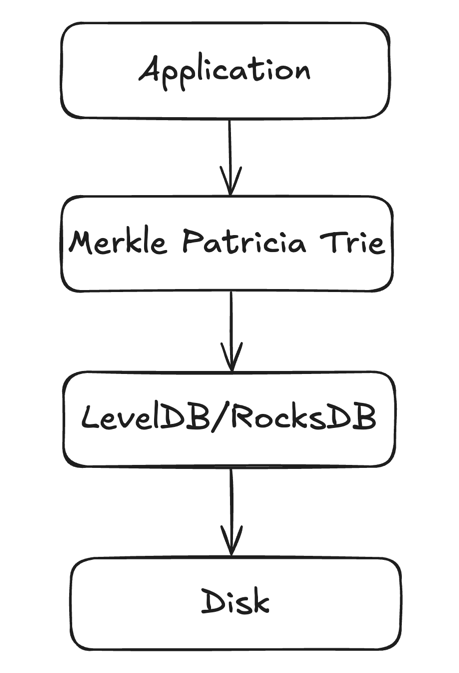
A read to the state involves traversing the MPT from its root down to the target leaf node. During this traversal, the MPT must fetch the content of each node from the backend database (if not cached). Due to the LSM tree structure of the database, each query itself involves multiple disk accesses. Consequently, a single read operation often translates into many I/O operations. This amplification effect worsens as the state size increases.
 *A simplified version of the Ethereum’s MPT (source: [CSDN](https://it007.blog.csdn.net/article/details/86551694?spm=1001.2101.3001.6650.19\&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-19-86551694-blog-79992072.pc_relevant_multi_platform_whitelistv1_exp2\&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-19-86551694-blog-79992072.pc_relevant_multi_platform_whitelistv1_exp2\&utm_relevant_index=25)). All keys have the same `a7` prefix so an extension node is created to save space and redundancy. The same goes for `a77d337` and `a77d397` which share the same `d3` prefix.*
The MPT aims to reduce redundancy and I/Os by compressing nodes with a single child to form so-called extension nodes. As reads need to query all nodes along the path from the root down to the target leaf node, extension nodes help reduce the number of queries. Extension nodes are more effective when the underlying data is sparse. However, as the state grows, the data becoming less sparse, effectively reducing the effects of extension nodes.
For a high-performance rollup like RISE targeting 100k+ TPS, this traditional architecture becomes a bottleneck. Every millisecond of latency in state access directly reduces the number of transactions RISE can process per second.
***
## RiseDB
RiseDB is a high-performance verifiable key-value store with a specific focus on efficiently managing the state of blockchain networks. One key objective of RiseDB is to achieve significantly faster state updates and access compared to existing solutions. This high throughput is compulsory for blockchains striving to support a large and active user set with numerous transactions.
### Unified Architecture
Traditional systems manage world state and Merkle trees separately, creating overhead and redundant operations. RiseDB merges world state and Merkle tree storage into a single, streamlined architecture, eliminating the overhead associated with managing separate layers, leading to more efficient data handling and merkleization processes. This unified design eliminates context switches between different storage engines, reduces data duplication, and streamlines state operations.
### Low Memory Footprint
The memory footprint of RiseDB is very small, allowing it to operate efficiently on consumer-grade computers, potentially lowering the barrier to entry for participating in blockchain networks. As a result, it enables broader node participation, reduces operational costs for node operators, and maintains the network's resilience by not requiring expensive infrastructure. Furthermore, the low memory footprint does not come at the cost of performance, RiseDB achieves high-speed operations while remaining memory-efficient.
### SSD-Optimized Access Patterns
RiseDB employs a storage design carefully tailored to leverage the strengths of modern SSDs, optimizing access patterns to maximize throughput and durability. By organizing data in a way that minimizes costly random writes and favors sequential, append-only operations, RiseDB efficiently utilizes SSD I/O capabilities.
*A simplified version of the Ethereum’s MPT (source: [CSDN](https://it007.blog.csdn.net/article/details/86551694?spm=1001.2101.3001.6650.19\&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-19-86551694-blog-79992072.pc_relevant_multi_platform_whitelistv1_exp2\&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-19-86551694-blog-79992072.pc_relevant_multi_platform_whitelistv1_exp2\&utm_relevant_index=25)). All keys have the same `a7` prefix so an extension node is created to save space and redundancy. The same goes for `a77d337` and `a77d397` which share the same `d3` prefix.*
The MPT aims to reduce redundancy and I/Os by compressing nodes with a single child to form so-called extension nodes. As reads need to query all nodes along the path from the root down to the target leaf node, extension nodes help reduce the number of queries. Extension nodes are more effective when the underlying data is sparse. However, as the state grows, the data becoming less sparse, effectively reducing the effects of extension nodes.
For a high-performance rollup like RISE targeting 100k+ TPS, this traditional architecture becomes a bottleneck. Every millisecond of latency in state access directly reduces the number of transactions RISE can process per second.
***
## RiseDB
RiseDB is a high-performance verifiable key-value store with a specific focus on efficiently managing the state of blockchain networks. One key objective of RiseDB is to achieve significantly faster state updates and access compared to existing solutions. This high throughput is compulsory for blockchains striving to support a large and active user set with numerous transactions.
### Unified Architecture
Traditional systems manage world state and Merkle trees separately, creating overhead and redundant operations. RiseDB merges world state and Merkle tree storage into a single, streamlined architecture, eliminating the overhead associated with managing separate layers, leading to more efficient data handling and merkleization processes. This unified design eliminates context switches between different storage engines, reduces data duplication, and streamlines state operations.
### Low Memory Footprint
The memory footprint of RiseDB is very small, allowing it to operate efficiently on consumer-grade computers, potentially lowering the barrier to entry for participating in blockchain networks. As a result, it enables broader node participation, reduces operational costs for node operators, and maintains the network's resilience by not requiring expensive infrastructure. Furthermore, the low memory footprint does not come at the cost of performance, RiseDB achieves high-speed operations while remaining memory-efficient.
### SSD-Optimized Access Patterns
RiseDB employs a storage design carefully tailored to leverage the strengths of modern SSDs, optimizing access patterns to maximize throughput and durability. By organizing data in a way that minimizes costly random writes and favors sequential, append-only operations, RiseDB efficiently utilizes SSD I/O capabilities.