# Continuous Block Pipeline (/docs/rise-evm/cbp)
# Continuous Block Pipeline (CBP)
## The Problem with Traditional Block Production
In typical Layer 2 systems, block production follows a strictly sequential process, where only a small portion of the total blocktime is spent on actual transaction execution. This inefficiency stems from the traditional flow.
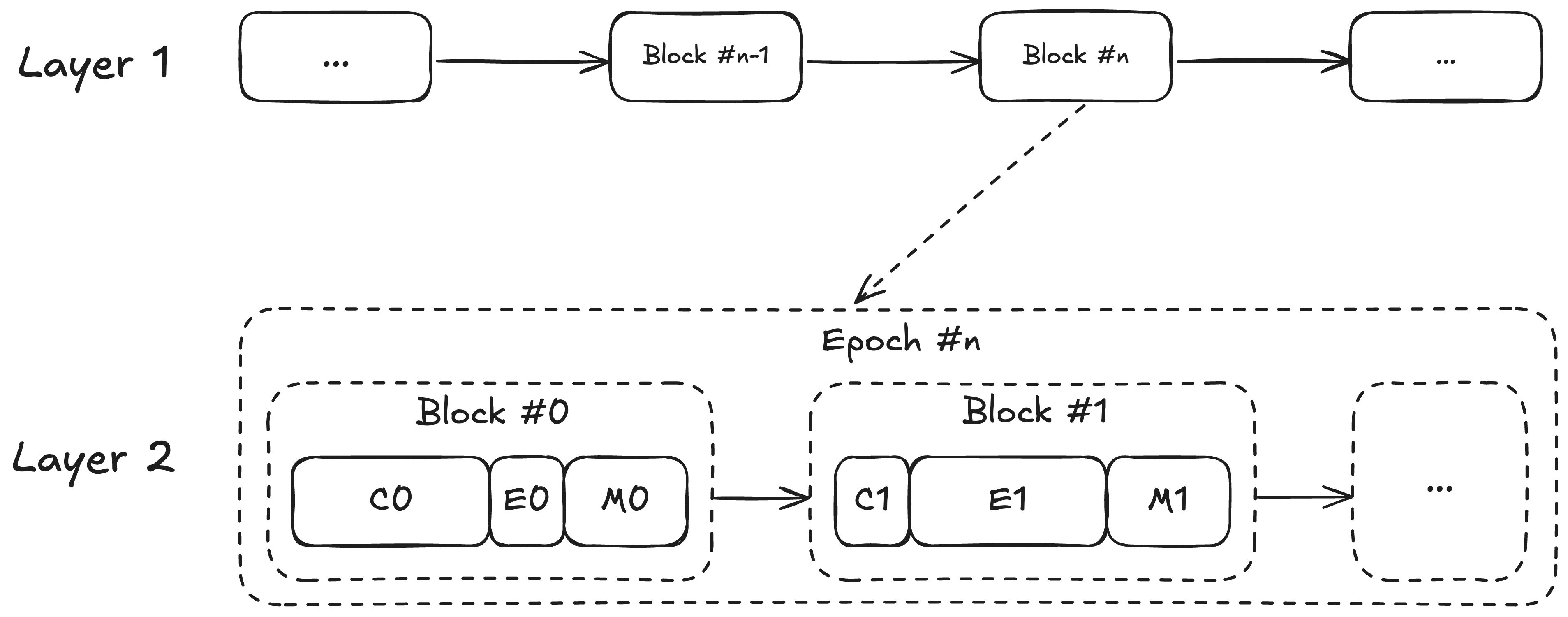
* **Consensus (C)**: Deriving L1 transactions and new block attributes. This phase blocks all other operations.
* **Execution (E)**: Executing derived transactions as well as L2 transactions from mempool. Execution is CPU-intensive.
* **Merkleization (M)**: Sealing the block by computing the new commitment to the state. Merkleization is IO-intensive and increases in cost as state size grows.
*A typical block pipeline for an L2 with a one-second block time and large state. The block gasLimit will be limited by how much gas can be processed in the time allocated to execution; however, in this system, execution accounts for only a minority of the block-building pipeline. The first block in an epoch has longer consensus time due to L1 and deposit derivation.*
Typically, these steps are sequential. As (C) and (M) can be slow, only a fraction of a block time is spent on executing user transactions sent to the mempool. This insufficient use of blocktime leads to poor performance on many L2s.
For instance, we measured in early 2024 that OP-Reth only spent 12%-36% of a second executing mempool transactions, meaning:
* If a hardware is fast enough to execute 10k transactions a second, the throughput is unfortunately capped at only 1200-3600 TPS.
* If a user transaction enters the mempool at an unlucky time, it may have to wait 640ms-880ms before processing, even without congestion.
## RISE's Continuous Block Pipeline
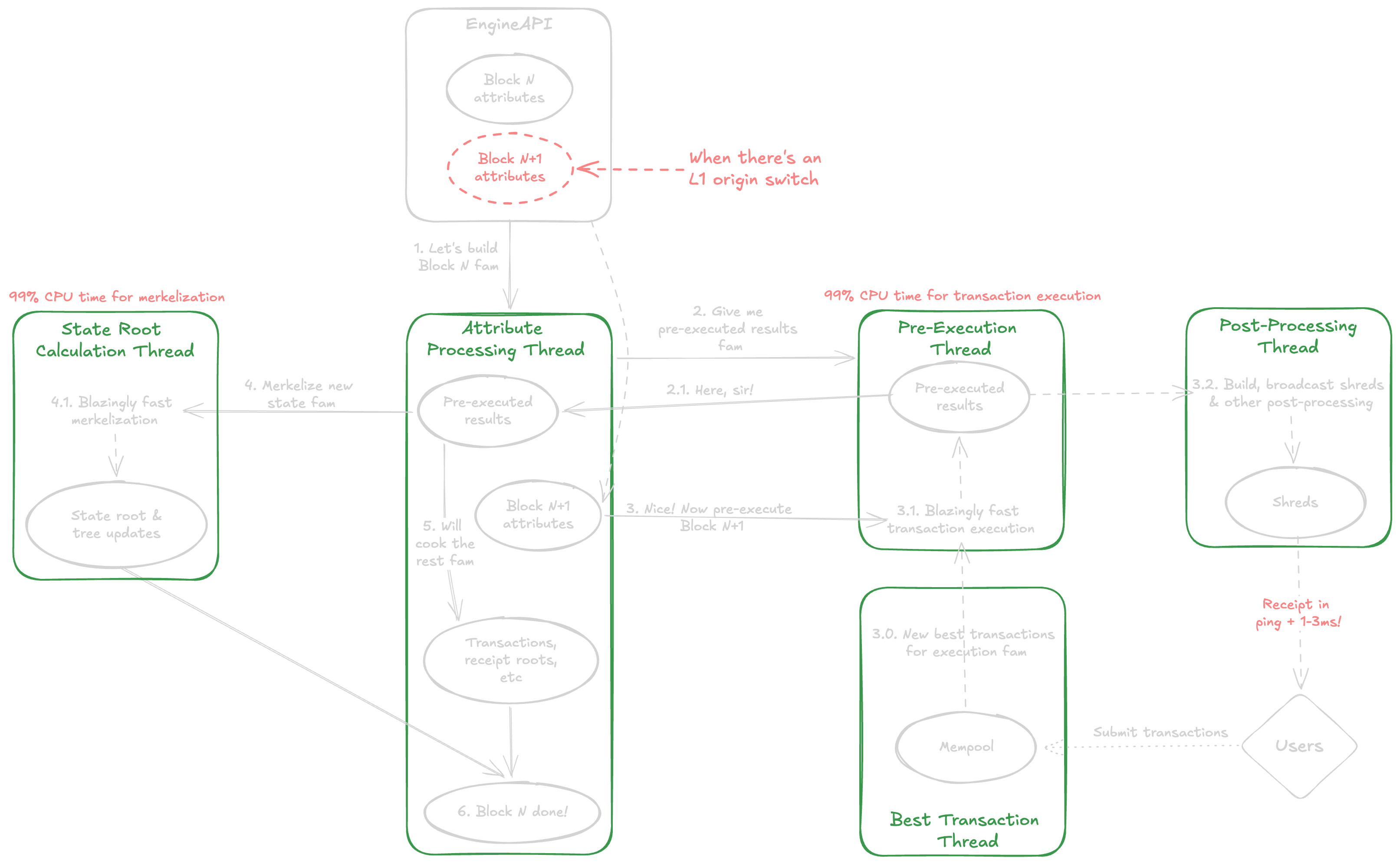
RISE introduces **a multi-threaded block pipeline that parallelizes key computations**, most importantly transaction execution and state root calculation.
There are currently 3 threads:
* A pre-execution thread constantly executes new L2 transactions from the mempool and no longer waits for CL to request a new block.
* A dedicated thread for state root calculation.
* A main driving thread that listens to new attributes and seals payloads from pre-executed results.
The key idea is to pre-execute transactions for the next block as we calculate the state root of the current pending block, and to calculate the state root in parallel to other payload calculations (transactions root, receipts root, etc.).
**The biggest effect is the RISE Block Pipeline executing transactions close to 100% of the available block time**.
This ensures throughput can go as high as the hardware physically can execute transactions. A longer L2 transaction processing duration per block also makes it easier for a user transaction to land on the pending block immediately, instead of needing to wait for the next block cycle. In fact, when there is no congestion, transactions are executed immediately as they hit the RPC server and get inserted into the mempool.
Furthermore, we override Reth's default implementation of `eth_getTransactionReceipt` to return receipts before the pending block is canonicalized, and add `eth_sendRawTransactionSync` ([EIP-7966](https://eips.ethereum.org/EIPS/eip-7966)) to submit a transaction and get back the receipt all-in-one round trip. Combined with [shreds](./shreds), the RISE Block Pipeline can return "real-time" receipts in ping plus 1\~3ms.
We also had successful experiments running extra threads for bringing in new mempool transactions, post-processing, parallel state root calculation, etc., but the works are still in progress. The key is to maximize CPU time for transaction execution, and to an extent also merkleization.
In conclusion, as is, RISE's Continuous Block Pipeline minimizes transaction (receipt) latency and 3x-8x the chain throughput.
## Key Challenges
### Pending Block Hash
Pre-execution doesn't have access to the state root of the parent block (being calculated in parallel), so any transaction trying to read it via the `BLOCKHASH` opcode or EIP-2935 would fail. We handle this by scheduling an in-time executed block at most every 12 seconds if we notice there's such a transaction. Most applications reading the pending block hash use it for on-chain randomness, for which we are encouraging dApps to replace with [much better on-chain VRF](https://blog.risechain.com/instant-blockchains-need-instant-randomness) anyway. Historical block hashes are unaffected.
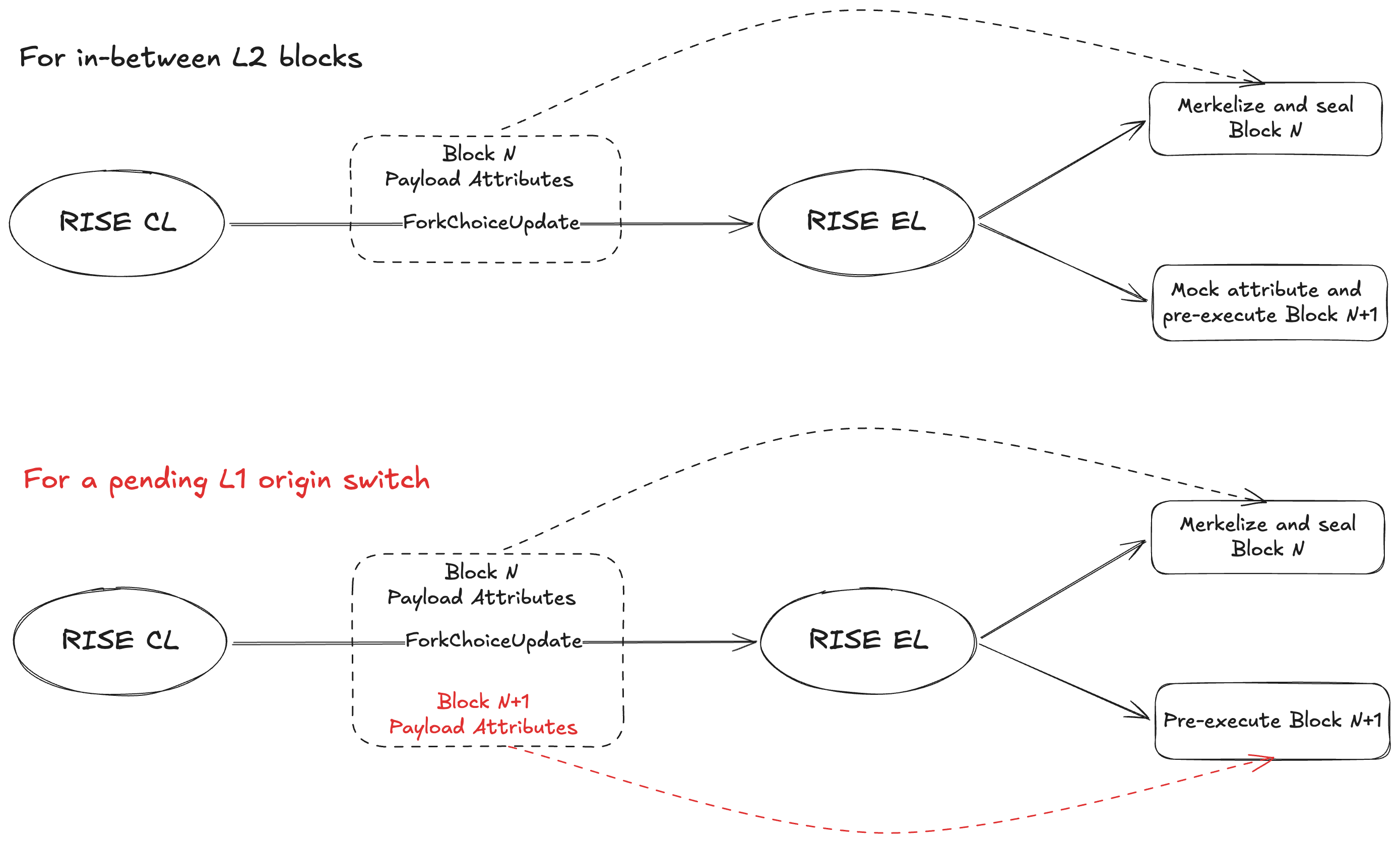
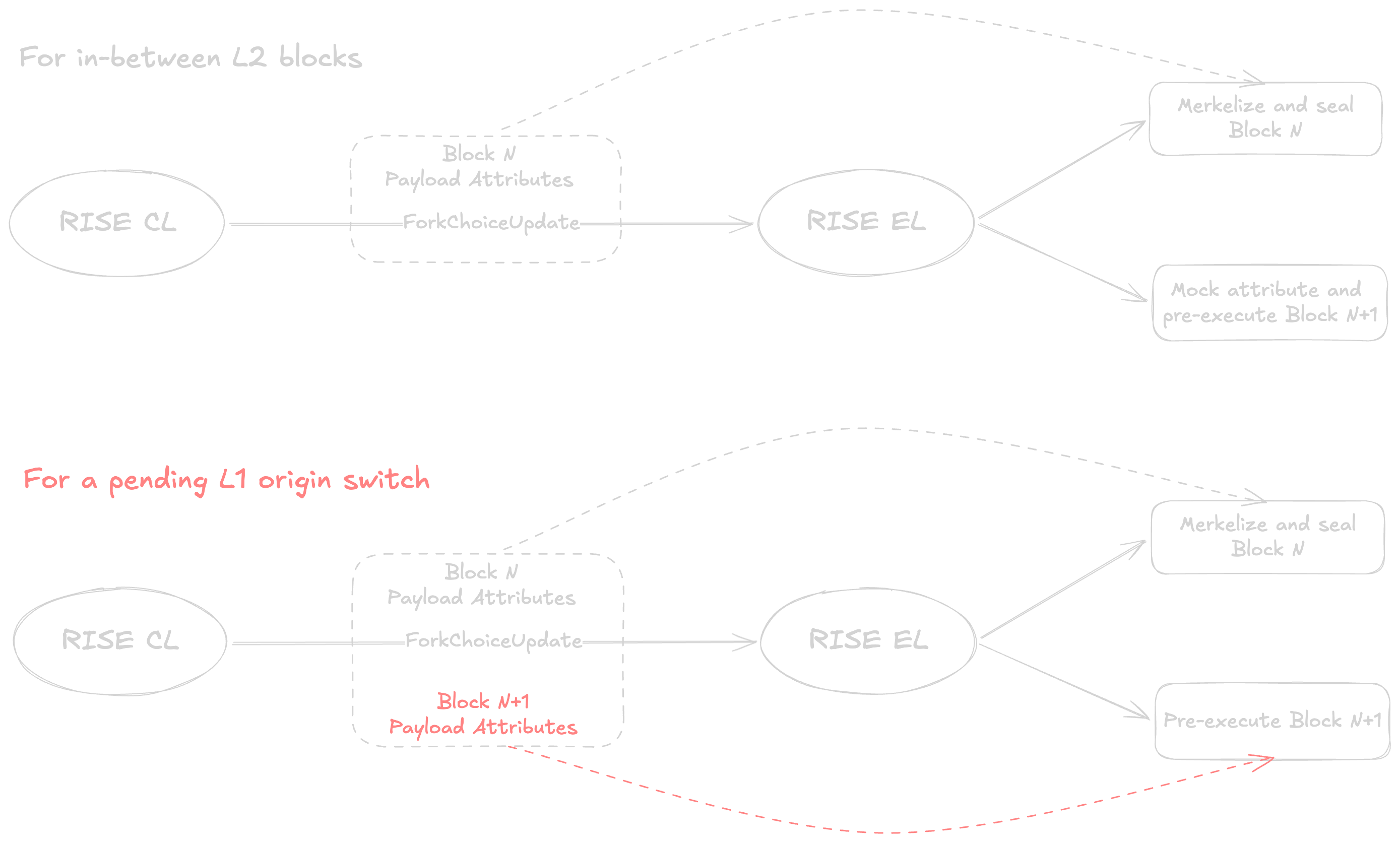
### L1 Origin Switches
L1 data like `PREVRANDAO` and deposits affect L2 state transitions. Naively pre-executing an L2 block with stale L1 data would lead to wrong state transitions. To handle this, we extend CL to send an extra set of payload attributes when there's an L1 origin switch, for pre-execution to start with the correct L1 data immediately. Otherwise, attributes are mocked for in-between L2 blocks, which only require counting up the sequence number of the first L1 Block Info transaction in the L2 block.
Long-term, we will replace Engine API with straightforward intra-process communication between an **L1 watcher** and the block pipeline.
## Ongoing & Future Plans
* Add a new thread for adding incoming transactions in parallel to transaction execution.
* Add a new thread for post-processing (shred building & broadcasting, etc.) in parallel to transaction execution.
* Add more threads for state root calculation, first for parallel storage roots, and then for the parallel sparse trie.
* Add more threads for execution with Parallel EVM.
* Merge CL with EL and replace network-based payloads (Engine API) with intra-process communication.